주요 개념
기본 아키텍쳐

마스터 노드
- 클러스터의 상태를 관리하고, 스케줄링 및 컨트롤을 담당하는 핵심 컴포넌트들이 동작하는 노드
- 여러 개의 핵심 컴포넌트 들의 집합으로 볼 수 있다
--> 결국은 kube-apiserver 를 사용해 외부에서 요청을 받고 적절한 내부 구성 요소와 통신하며 그 요청을 수행한다.
마스터 노드의 구성 요소로는 kube-apiserver, etcd, kube-scheduler, controller-manager 등이 있다.
클러스터는 마스터노드와 워커노드 전체를 포함하는 하나의 운영 단위를 의미한다
워커 노드
- Pod(컨테이너의 집합)을 실행하고, 네트워크 및 볼륨을 관리하며, 애플리케이션이 실행되는 환경을 제공
- 마스터 노드에서 내려준 명령을 수행하는 실행 단위
Pod는 하나의 단일 인스턴스로 보면 된다
etcd
- Kubernetes의 모든 상태 정보를 저장하는 분산 키-값 저장소
- 단순 저장 공간이 아니라 클러스터 상태의 단일 진실 공급원 역할을 함
kube-scheduler
- 새로운 Pod가 생성되었을 때, 이를 실행할 적절한 워커 노드를 찾아 할당하는 역할 (할당만함)
- CPU, 메모리, 스토리지 사용량 및 affinity/anti-affinity 정책 등을 고려하여 최적의 노드를 선택함.
controller-manager
- 클러스터의 원하는 상태(desired state)를 유지하도록 다양한 컨트롤러가 동작하는 컴포넌트
여러 개의 컨트롤러들이 모여 있는 집합체이며, 대표적으로 아래 컨트롤러들이 포함된다
• Node Controller: 노드가 다운되었는지 감지하고 대응.
• Replication Controller: Pod 개수를 유지하여 원하는 개수만큼 실행되도록 관리.
• Deployment Controller: 새로운 버전의 애플리케이션을 롤링 업데이트.
• Job Controller: 일회성 작업 관리.
kubelet
- 각 워커 노드에서 실행되며, kube-apiserver와 통신하여 Pod의 상태를 관리하고 컨테이너 런타임(Docker, containerd 등)과 상호 작용하는 에이전트
- kube-apiserver는 단순히 지시만 하는 것이 아니라, kubelet이 주기적으로 노드 상태를 보고함.
- kubelet은 노드가 비정상적인 경우 이를 감지하여 컨테이너를 재시작하거나, 실패한 Pod를 재배치하는 등의 역할을 함.
kube-proxy
- 클러스터 내부의 네트워크 통신을 관리하며, 서비스(Service) 객체를 통해 로드 밸런싱과 프록시 역할을 수행
- Kubernetes의 Service는 Pod 간에 안정적인 네트워크 주소를 제공하는데, kube-proxy가 이를 지원
- iptables 또는 IPVS를 활용하여 네트워크 트래픽을 관리
kube-apiserver
- 클러스터의 핵심 API 엔드포인트로, 모든 Kubernetes 컴포넌트 및 외부 클라이언트(kubectl, API 호출 등)가 접근하는 인터페이스 제공
- 클러스터 상태를 변경하는 모든 요청은 kube-apiserver를 통해 이루어짐
- 인증(Authentication), 권한 부여(Authorization), admission control 등을 수행.
컨테이너 런타임
- Kubernetes는 컨테이너 런타임 인터페이스(Container Runtime Interface, CRI)를 통해 다양한 런타임을 지원한다
- Docker뿐만 아니라, containerd, CRI-O 같은 다른 런타임도 사용 가능
- 현재 Kubernetes에서는 Docker 대신 containerd를 기본 런타임으로 권장.
Docker는 원래 컨테이너 기반 가상화 기술을 제공하는 컨테이너 플랫폼이다. 하지만 Kubernetes에서는 “컨테이너 런타임(Container Runtime)“의 역할로만 사용된다.
즉, Kubernetes가 직접 애플리케이션을 실행하는 것이 아니라, 컨테이너 런타임(예: Docker, containerd, CRI-O 등)을 이용해 컨테이너를 실행하는 역할만 한다.
컨테이너 런타임(Container Runtime)이란?
• 컨테이너를 생성, 실행, 관리하는 소프트웨어
• Kubernetes가 Pod 내부에서 실행해야 할 컨테이너를 컨테이너 런타임에게 요청하면, 런타임이 이를 실행하는 방식.
Kubernetes의 워크플로우
1. 사용자가 kubectl apply -f deployment.yaml을 실행.
2. kubectl이 kube-apiserver에 요청을 보냄.
3. kube-apiserver는 요청을 검증하고 etcd에 저장.
4. controller-manager가 상태 변화를 감지하고 필요한 Pod를 생성하도록 요청.
5. kube-scheduler가 적절한 워커 노드를 선택하여 배치.
6. kubelet이 컨테이너 런타임(Docker, containerd)을 호출하여 실제 컨테이너 실행.
7. kube-proxy가 네트워크를 설정하여 Service와 Pod 간 통신을 지원.
Docker/ ContainerD
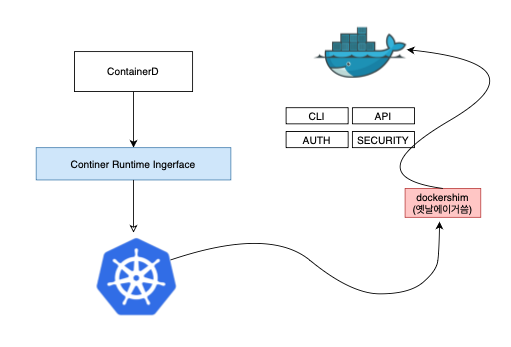
Docker와 containerd는 같은 컨테이너 생태계에 속하지만, 역할이 다르다.
| Docker | containerD | |
| 역할 | 컨테이너 관리 플랫폼 (컨테이너 빌드, 실행, 네트워크, 스토리지 등 포함) | 컨테이너 런타임 (컨테이너 실행 및 관리만 담당) |
| 구성 요소 | CLI (docker), API, Docker Daemon, containerd, runc 포함 | containerd, runc 포함 (더 가볍고 최소한의 기능) |
| 쿠버네티스 호환성 | dockershim을 사용해 Kubernetes에서 지원했지만(초기에 docker가 cri를 지원하지 않았기 때문), v1.24부터 제거됨 | CRI(Container Runtime Interface)를 기본 지원하여 Kubernetes에서 직접 사용 가능 |
| OCI 호환성 | OCI(Open Container Initiative) 기반이지만, 독자적인 요소 포함 | OCI 완전 호환 |
| 설치 방법 | Docker 설치 시 내부적으로 containerd 포함 | containerd만 별도로 설치 가능 |
| 사용자 인터페이스 | 친숙한 CLI (docker 명령어) 제공 | 기본 CLI(ctr)가 불편하여 nerdctl 등 별도 도구 사용 |
Docker는 전체적인 컨테이너 관리 도구, containerd는 컨테이너 실행기이다
- Docker는 컨테이너 빌드, 이미지 관리, 네트워크, 볼륨, 런타임 등 다양한 기능을 포함하는 플랫폼.
- containerd는 컨테이너 실행 및 관리만 담당하는 최소한의 런타임.
즉, containerd는 Docker의 일부였지만, 쿠버네티스에서 컨테이너 실행 기능만 필요했기 때문에 분리
이미지 스펙 OCI 표준
OCI(Open Container Initiative)는 컨테이너 이미지 및 런타임의 표준을 정의하는 프로젝트
• Docker가 처음 컨테이너 기술을 주도했지만, 독점적인 포맷을 사용하면서 생태계가 분열될 위험이 있었음.
• 이를 해결하기 위해 **OCI(Open Container Initiative)**가 만들어졌고, 모든 컨테이너 이미지와 런타임이 동일한 표준을 따르도록 함.
• containerd는 OCI를 완벽하게 지원하지만, Docker는 일부 자체적인 기능을 포함함.
런타임
어떤 프로그램이 실제로 실행되는 시점을 의미해. 즉, 소프트웨어가 실행되고 동작하는 동안의 환경을 뜻하는 개념
- 개발(Development): 코드 작성 및 컴파일
- 배포(Deployment): 실행할 준비 완료
- 실행(Runtime): 애플리케이션이 실제로 실행되는 단계
ex) Java 애플리케이션은 JVM(Java Virtual Machine) 위에서 실행됨 → JVM이 Java의 런타임 환경,
컨테이너는 Docker, containerd 같은 컨테이너 런타임에서 실행됨 → 컨테이너 런타임이 컨테이너 실행 환경
(참고로 컨테이너는 이미지에서 만들어진 실행 환경이다, 컨테이머이미지 안에 파일과 설정등 불편한 패키지가 있고 이게 컨테이너를 만들기 위한 템플릿 이라고 보면된다)
ETCD
etcd는 분산되고 신뢰할 수 있는 key-value 스토어로 Kubernetes에서는 클러스터 상태를 저장하는 핵심 데이터 저장소 역할을 한다.
📌특징
• 분산(Distributed): 여러 노드에 걸쳐 데이터를 저장하고, 장애 발생 시 데이터 손실 없이 복구 가능.
• 신뢰성(Reliable): Raft consensus algorithm을 사용하여 강력한 일관성(Strong Consistency)을 보장.
• 빠름(Fast): 고성능 key-value 저장소로 빠른 읽기/쓰기 가능.
• 보안(Secure): TLS 암호화를 지원하여 안전한 데이터 저장.
Raft Consensus 알고리즘
분산 시스템에서 노드들이 하나의 정확한 상태를 유지하기 위한 합의를 이루는 알고리즘
(데이터의 일관서을 유지하는 핵심 알고리즘)
-> Raft는 분산 환경에서 하나의 리더를 선출하고 다른 노드들이 이를 따르는 방식으로 작동한다.
etcd 설치 및 기본 사용법
--바이너리 다운로드
wget https://github.com/etcd-io/etcd/releases/latest/download/etcd-linux-amd64.tar.gz
--압축해제
tar -xvf etcd-linux-amd64.tar.gz
cd etcd-linux-amd64
-- 실행
./etcd
(기본적으로 2379 포트에서 서비스 실행)
etcd는 명령어 기반의 클라이언트 도구인 etcdctl을 제공함.
저장 : ./etcdctl put key1 "value1"
조회 : ./etcdctl get key1
삭제 : ./etcdctl del key1
etcd는 CLI(etcdctl)뿐만 아니라 HTTP gRPC API도 제공한다
- 버전별 API
v2 API: 기존 RESTful API 방식
v3 API: gRPC 기반으로 변경 (성능 최적화)
📌Kubernetes에서의 etcd 역할
Kubernetes에서 etcd는 클러스터의 모든 상태를 저장하는 중앙 저장소 역할을 한다.
저장되는 주요 데이터
• 클러스터의 노드(Node) 정보
• Pod 정보
• ConfigMaps, Secrets (설정 및 민감 정보)
• Service, Deployments, ReplicaSets 등
• RBAC(Role-Based Access Control) - 계정, 역할, 권한 정보
👉 즉, Kubernetes의 모든 리소스 정보가 etcd에 저장되며, 변경이 발생할 때마다 etcd가 업데이트됨.
👉 etcd에 데이터가 정상적으로 반영되어야 Kubernetes에서 작업이 완료된 것으로 간주된다.
📌 Kubernetes에서 etcd 배포 방법
Kubernetes에서 etcd는 클러스터 설정 방식에 따라 배포 방법이 다름.
수동 배포 (From Scratch)
• etcd를 직접 바이너리 설치 후 수동으로 구성하는 방식.
• etcd의 설정을 직접 커스터마이징할 수 있지만, 관리가 어려울 수 있음.
kubeadm을 이용한 자동 배포
• kubeadm을 사용하면 Kubernetes 시스템에서 자동으로 etcd를 배포.
• etcd는 kube-system 네임스페이스 내에서 Pod 형태로 실행됨.
• Kubernetes 클러스터에서 기본적으로 제공하는 방식.
| 장점 | 단점 | |
| 수동 배포 (From Scratch) | 고도의 커스터마이징 가능 | 설정이 복잡하고 유지보수 어려움 |
| kubeadm 배포 | 관리가 쉽고 자동화 가능 | 기본 설정 외 커스터마이징 어려움 |
📌 etcd 데이터 저장 구조 (Kubernetes 기준)
Kubernetes에서 etcd는 특정한 디렉터리 구조로 데이터를 저장한다.
/registry
├── minions (노드 정보)
├── pods (Pod 정보)
├── replicasets (ReplicaSet 정보)
├── deployments (Deployment 정보)
├── roles (RBAC 역할 정보)
├── secrets (보안 정보)
즉, /registry 아래에 Kubernetes의 모든 리소스 정보가 저장된다.
이를 통해 etcd를 백업하면 Kubernetes의 전체 클러스터 상태를 복원할 수도 있다.
📌 etcd의 고가용성 (HA) 구성
고가용성(HA, High Availability)을 위해 etcd를 여러 개의 노드에 분산 배치할 수 있음.
HA 구성에서 중요한 점
1. 마스터 노드가 여러 개일 경우, etcd도 여러 개 배포됨.
2. etcd 노드들 간에 통신이 가능해야 함.
- etcd 클러스터 간 통신을 위해 특정 매개변수를 설정해야 함 (--initial-cluster 옵션 등).
3. etcd는 홀수(3개, 5개 등)로 구성해야 함.
- Raft consensus 알고리즘을 사용하기 때문에 과반수(Majority)가 필요함.
👉 각 etcd 노드는 서로 통신할 수 있도록 설정해야 함.
👉 클러스터 내 과반수(etcd 노드 3개 중 최소 2개)가 살아 있어야 정상적으로 동작.
Kube-API server
Kubernetes의 중앙 관리 컴포넌트로, 모든 요청을 처리하는 핵심 요소로
kubectl 명령 실행 시, 해당 요청이 kube-apiserver로 전달된다.
요청이 오면 이를 인증(authentication) 및 검증(validation) 한 후 동작을 처리해서 데이터를 리턴한다.
모든 kubernetes 컴포넌트들이 kube-apiserver를 통해 클러스터 상태를 변경하고 kube-apiserver가
유일하게 etcd와 직접 통신하는 컴포넌트이다.
(요청이 왔을때 해당하는 요청에 맞게 scheduler, etcd, kubelet등과 통신 하면서 일을 처리함)
Kube Controller Manager
kube controller manger 는 Kubernetes의 컨트롤러들을 관리하는 핵심 컴포넌트
컨트롤러는 클러스터의 상태를 지속적으로 모니터링하고, 원하는 상태(desired state)를 유지하기 위한 조치를 수행한다.
그리고 다양한 컨트롤러들이 패키징되어 하나의 프로세스로 실행된다.
(설치는 Kubernetes 공식 릴리즈 페이지에서 다운로드할 수 있으며 설치시 다양한 옵션을 지정해서 동작 커스터마이징 가능)
컨트롤러의 역할
클러스터 내 리소스의 상태를 감시하고, 변경이 필요할 경우 적절한 액션 수행.
대표적인 컨트롤러:
• 노드 컨트롤러 (Node Controller):
- 노드 상태를 감시하여 5초마다 헬스 체크 수행.
- 40초 동안 응답이 없으면 노드를 unreachable로 표시, 5분 이상 복구되지 않으면 해당 노드의 파드를 삭제하고 다른 노드에 재배치.
• 복제 컨트롤러 (Replication Controller):
- ReplicaSet을 모니터링하고, 원하는 개수의 파드가 유지되도록 보장.
- 파드가 삭제되면 새로운 파드를 자동 생성하여 복구.
그 외에도 Deployment, Service, Namespace, Persistent Volume 관리 등의 컨트롤러 포함.
Kube Scheduler
- Kubernetes에서 Pod를 적절한 노드에 배치하는 역할을 수행.
- Pod를 직접 생성하는 것이 아니라, 어떤 노드에 배치할지 결정하는 것만 담당.
- Pod를 배치한 후, 실제로 노드에 배포하는 작업은 kubelet이 수행.
스케줄링 과정
스케줄러는 두 단계를 거쳐 최적의 노드를 선택:
1. 필터링 단계 (Filtering)
- Pod가 필요한 CPU, 메모리 등의 자원을 충족하지 못하는 노드 제거.
- Taints & Tolerations, Node Selectors, Affinity 등의 규칙도 적용.
2. 우선순위 평가 단계 (Scoring & Ranking)
- 남아있는 노드들에 대해 우선순위를 평가하여 점수를 매김 (0~10 점수 기준)
- 예: Pod 배치 후 남는 CPU가 많은 노드가 더 높은 점수를 받을 수 있음.
- 가장 높은 점수를 받은 노드가 Pod의 배치 대상 노드로 선정.
스케줄링 정책 및 커스텀 스케줄러
기본 스케줄러 외에도, 사용자가 직접 스케줄링 로직을 정의할 수도 있음.
주요 스케줄링 조건
- 리소스 요구사항 (CPU, 메모리)
- Taints & Tolerations (특정 노드에 특정 Pod만 배치하도록 설정)
- Node Selectors & Affinity (특정 노드 그룹에 Pod를 배치)
- Pod Topology Spread Constraints (Pod를 여러 노드에 균등 분배)
설치 및 실행
Kubernetes 공식 릴리즈 페이지에서 kube-scheduler 바이너리를 다운로드 후 실행.
실행 시 스케줄러 설정 파일을 지정하여 동작을 커스터마이징 가능.
Kubelet
Kubelet은 Kubernetes 워커 노드에서 실행되는 핵심 에이전트. ( 노드별로 하나씩 kubelet 설치)
- 마스터 노드의 kube-scheduler로부터 Pod 배포 명령을 받아 실행.
- 노드 및 컨테이너 상태를 모니터링하여 주기적으로 kube-apiserver에 보고.
Kubelet의 주요 역할
- 노드를 Kubernetes 클러스터에 등록
- 클러스터에 소속되는 노드로 등록을 한다는 뜻 (등록전에는 해당 클러스터에 등록이 안되어있는것)
- 등록할떄 인증 절차가 있다
- Pod 생성 및 관리
- 스케줄러의 지시에 따라 Pod를 생성하고 실행.
- 컨테이너 런타임(Docker, containerd 등)에 이미지 다운로드 및 컨테이너 실행 요청.
- 상태 모니터링 및 보고:
- Pod 및 컨테이너의 상태를 지속적으로 점검.
- 이 정보를 kube-apiserver에 주기적으로 전송하여 클러스터 상태 관리.
설치 및 실행
kubeadm을 사용해 클러스터를 설치해도 kubelet은 자동으로 설치되지 않음 → 바이너리 다운로드 후 서비스로 실행.
Kube Proxy
Kube Proxy는 Kubernetes에서 서비스(Service) 네트워크 트래픽을 관리하는 역할을 수행한다.
각 노드마다 하나씩 실행되는 프로세스로, Pod 간 네트워크 통신을 가능하게 한다. (서비스의 IP 주소를 Pod로 매핑하여 트래픽을 전달)
(각 노드에서 하나씩 실행되지만 노드 내부의 pod끼리만 통신 x 다른 노드의 pod와도 통신 가능)
서비스(Service)는 Kubernetes 클러스터 내에서 Pod에 안정적인 네트워크 접점을 제공하는 논리적인 리소스
서비스는 고정된 엔드포인트를 제공해서 pod에 안정적으로 접근할 수 있도록 해준다
- 서비슨느 pod 앞에 위치해서 로드 밸런싱과 트래픽 전달 (1:1매핑 x, 특정 pod 집합에 대한 하나의 엔트포인트 제공)
- kubernetes 내부 dns 시스템과 연동되어 서비스 이름으로 접근 가능
kube-proxy의 주요 기능
✅ 서비스 트래픽을 적절한 백엔드 Pod로 전달
✅ iptables 또는 IPVS를 사용하여 트래픽을 라우팅
✅ 각 노드에서 실행되며, 새로운 서비스가 생성되면 자동으로 트래픽 규칙을 설정
iptables: 네트워크 트래픽이 어디로 갈지 정하는 교통경찰 역할을 하는 Linux의 기본 방화벽 및 라우팅 시스템.
IPVS (IP Virtual Server): 더 많은 차선을 가진 고속도로 톨게이트처럼, 많은 트래픽을 빠르게 여러 서버(Pod)로 분산시키는 고성능 로드 밸런서.
서비스 네트워크 설정 과정
1. Pod 네트워크
모든 Pod는 클러스터 내부 가상 네트워크(CNI)에 연결됨.
Pod 간에는 직접 통신 가능하지만, Pod의 IP는 동적으로 변경될 수 있음.
2. 서비스(Service) 생성
특정 Pod에 대한 고정된 접근점을 제공하는 가상 네트워크 객체.
내부 클러스터에서 고정된 서비스 IP를 부여받음. (kube-apiserver가 할당하고 관리하는거, ClusterIP 범위내에서 할당)
하지만 서비스 자체는 실제로 존재하는 컨테이너가 아니며, 논리적 개념.
3. kube-proxy가 트래픽 규칙 설정
서비스가 생성되면, kube-proxy가 각 노드에서 iptables 규칙을 설정.
예를 들어, 서비스 10.96.0.12가 실제 Pod 10.32.0.15로 트래픽을 전달하도록 규칙을 생성.
클러스터 내부에서 DB 서비스의 이름 또는 IP를 사용하면, kube-proxy가 올바른 Pod로 트래픽을 전달
(Pod가 삭제되거나 새로 생성될 때, kube-proxy는 자동으로 iptables 규칙을 업데이트해서 새로운 Pod로 트래픽을 보낼 수 있도록 유지)
kube-proxy의 동작 방식
iptables 모드
iptables를 사용해 서비스 IP → Pod IP로 NAT 변환 수행.
작은 규모의 클러스터에서 효율적.
IPVS 모드
IPVS(IP Virtual Server)를 사용해 더 빠르고 효율적인 로드 밸런싱 제공.
대규모 클러스터에서 더 좋은 성능을 발휘.
설치 및 실행
• kubeadm을 사용하면 kube-proxy가 자동으로 DaemonSet 형태로 배포됨.
• DeamonSet 으로 인해서 각 노드에 하나의 kube-proxy Pod가 항상 실행된다
'자격증 > CKA' 카테고리의 다른 글
| cluster 관리 (0) | 2025.04.12 |
|---|---|
| Lifecycle Management (2) | 2025.04.06 |
| Logging & Monitoring (0) | 2025.04.06 |
| 쿠버네티스 Scheduling (0) | 2025.03.31 |
| 구성 요소 설계 및 생성 (0) | 2025.03.08 |
